Francesco Pittaluga

Senior Researcher at NEC Labs America
Media Analytics Department
francescopittaluga at nec-labs dot com
Francesco is a senior researcher in the Media Analytics Department at NEC Labs America, where he focuses on computer vision, autonomous driving, and privacy. Prior to joining NEC Labs, he completed his Ph.D. in Electrical Engineering at the University of Florida, working in the FOCUS Lab under the supervision of Sanjeev J. Koppal. As a Ph.D. candidate, he was awarded a Microsoft Research Dissertation Grant and also interned at the Toyota Technological Institute at Chicago (TTIC), where he collaborated with Ayan Chakrabarti; at Magic Leap's Advanced Technology Lab, where he worked with Laura Trutoiu and Brian Schowengerdt; and at Microsoft Research, where he collaborated with Sudipta Sinha and Sing Bing Kang. Before embarking on his doctoral studies, he earned B.S. degrees in both Electrical Engineering and in Computer Science from Tufts University and conducted undergraduate research under the guidance of Karen Panetta. During that time, he also interned at GE Intelligent Platforms and took part in the National Science Foundation Research Experience for Undergraduates Program at Florida International University.
Tufts University
2010-2014
University of Florida
2014-2019
Toyota Technological
Institute at Chicago
Fall 2016
Magic Leap
Advanced Tech. Lab
Summer 2017
Microsoft Research
Summer 2018
NEC Labs America
2019-Present
News
| 06/26 - | HorizonWeaver: Generalizable Multi-Level Semantic Editing for Driving Scenes accepted to CVPR 2026. |
| 06/26 - | HorizonForge: Driving Scene Editing with Any Trajectories and Any Vehicles accepted to CVPR 2026. |
| 04/25 - | LangTraj: Diffusion Model and Dataset for Language-Conditioned Trajectory Simulation accepted to ICCV 2025. |
| 01/25 - | Awarded First Place Prize ($750,000) in U.S. Department of Transportation Intersection Safety Challenge 2025! |
| 09/24 - | SafeSim: Safety-Critical Closed-Loop Traffic Simulation with Diffusion-Controllable Adversaries accepted to ECCV 2024. |
| 09/24 - | OpEnCam: Lensless Optical Encryption Camera published to TCI 2024. |
| 12/23 - | DP-Mix: Mixup-based Data Augmentation for Differentially Private Learning accepted to NeurIPS 2023. |
| 10/23 - | LDP-Feat: Image Features with Local Differential Privacy accepted to ICCV 2023. |
| 12/22 - | Voting-based Approaches For Differentially Private Federated Learning published at NeurIPSW 2022. |
| 10/22 - | Learning Phase Mask for Privacy-Preserving Passive Depth Estimation accepted to ECCV 2022. |
| 03/21 - | Divide-and-Conquer for Lane-Aware Diverse Trajectory Prediction accepted to CVPR 2021. |
| 10/20 - | Towards a MEMS-based Adaptive LIDAR accepted to 3DV 2020. |
| 07/20 - | SMART: Simultaneous Multi-Agent Recurrent Trajectory Prediction accepted to ECCV 2020. |
| 02/20 - | Revealing Scenes by Inverting SfM Reconstructions featured in Computer Vision News. |
| 10/19 - | Joined the Media Analytics Department at NEC Labs America as a researcher. |
| 06/19 - | Revealing Scenes by Inverting SfM Reconstructions published at CVPR 2019 (Best Paper Finalist). |
| 06/19 - | Presented Privacy-Preserving Action Recognition using Coded Aperture Videos at CVPRW 2019. |
| 06/19 - | Revealing Scenes by Inverting SfM Reconstructions featured in the Microsoft Research Blog. |
| 05/19 - | Received a PhD in Electrical Engineering from the University of Florida. |
| 04/19 - | Received Attributes of a Gator Engineer Award from UF Herbert Wertheim College of Engineering. |
| 03/19 - | Defended dissertation! Thank you commitee members: Sanjeev Koppal, José Principe, Baba Vemuri and Kevin Butler. |
| 01/19 - | Presented Learning Privacy-Preserving Encodings through Adversarial Training at WACV 2019. |
| 06/18 - | Awarded Microsoft Research Dissertation Grant for work on Privacy-Preserving Computational Cameras. |
| 05/18 - | Joined Microsoft Research as a research intern. |
Publications
Autonomous Driving
2026 | LangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
Yun He, Francesco Pittaluga, Ziyu Jiang, Matthias Zwicker, Manmohan Chandraker, Zaid Tasneem

LangDriveCTRL is a natural-language-controllable framework for editing real-world driving videos to synthesize diverse traffic scenarios. It represents each video as an explicit 3D scene graph, decomposing the scene into a static background and dynamic object nodes. To enable fine-grained editing and realism, it introduces a feedback-driven agentic pipeline: an Orchestrator converts user instructions into executable graphs that coordinate specialized multi-agents and tools; an Object Grounding Agent aligns free-form text with target object nodes; a Behavior Editing Agent generates multi-object trajectories from language instructions; and a Behavior Reviewer Agent iteratively reviews and refines the generated trajectories. The edited scene graph is rendered and harmonized using a video diffusion tool, then further refined by a Video Reviewer Agent to ensure photorealism and appearance alignment. LangDriveCTRL supports both object node editing (removal, insertion, and replacement) and multi-object behavior editing, achieving photorealism, instruction alignment, structure preservation, and traffic realism simultaneously, significantly outperforming prior methods.
2026 | RAD-LAD: Rule and Language Grounded Autonomous Driving in Real-Time
Anurag Ghosh, Srinivasa Narasimhan, Manmohan Chandraker, Francesco Pittaluga
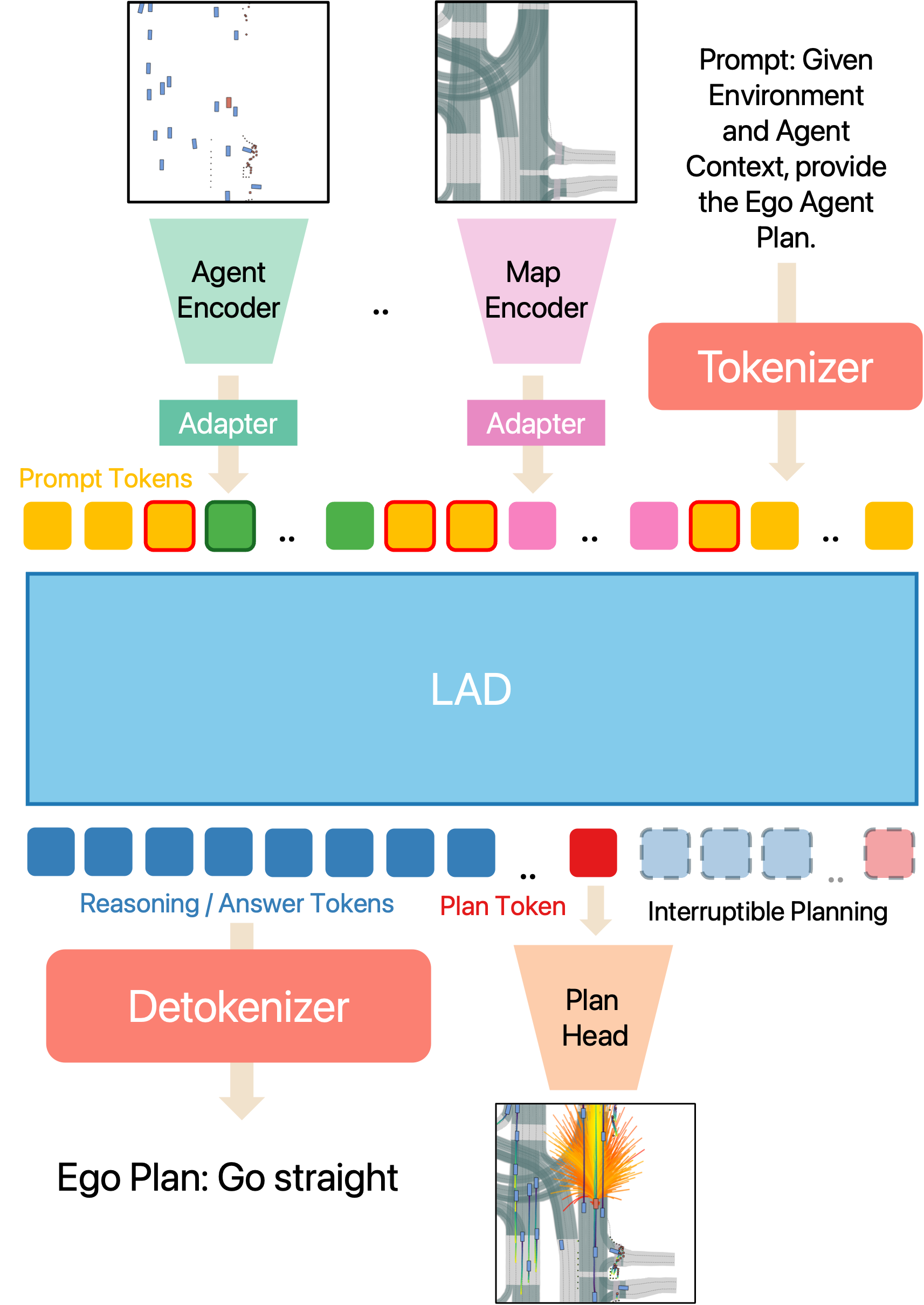
We present LAD, a real-time language-action planner with an interruptible architecture that produces a motion plan in a single forward pass (~20 Hz) or generates textual reasoning alongside a motion plan (~10 Hz). LAD is fast enough for real-time closed-loop deployment, achieving ~3x lower latency than prior driving language models while setting a new learning-based state of the art on nuPlan Test14-Hard and InterPlan. We also introduce RAD, a rule-based planner designed to address structural limitations of PDM-Closed; RAD achieves state-of-the-art performance among rule-based planners on nuPlan Test14-Hard and InterPlan. Finally, we show that combining RAD and LAD enables hybrid planning that captures the strengths of both approaches. This hybrid system demonstrates that rules and learning provide complementary capabilities: rules support reliable maneuvering, while language enables adaptive and explainable decision-making.
CVPR 2026 | HorizonWeaver: Generalizable Multi-Level Semantic Editing for Driving Scenes
Mauricio Soroco, Francesco Pittaluga, Zaid Tasneem, Abhishek Aich, Bingbing Zhuang, Wuyang Chen, Manmohan Chandraker, Ziyu Jiang

Ensuring safety in autonomous driving requires scalable generation of realistic, controllable driving scenes beyond what real-world testing provides, yet existing instruction-guided image editors, trained on object-centric or artistic data, struggle with dense, safety-critical driving layouts. We propose HorizonWeaver, which tackles three fundamental challenges in driving scene editing: (1) multi-level granularity, requiring coherent object- and scene-level edits in dense environments; (2) rich high-level semantics, preserving diverse objects while following detailed instructions; and (3) ubiquitous domain shifts, handling changes in climate, layout, and traffic across unseen environments. The core of HorizonWeaver is a set of complementary contributions across data, model, and training: large-scale paired real/synthetic dataset generation from Boreas, nuScenes, and Argoverse2 to improve generalization; Lang-Masks, where semantics-enriched masks and prompts enable precise, language-guided edits; and joint losses that enforce content preservation and instruction alignment. Collecting 255K images across 13 editing categories, HorizonWeaver outperforms prior methods in L1, CLIP, and DINO metrics, achieving +46.4% user preference and improving BEV segmentation IoU by +33%.
CVPR 2026 | HorizonForge: Driving Scene Editing with Any Trajectories and Any Vehicles
Yifan Wang, Francesco Pittaluga, Zaid Tasneem, Chenyu You, Manmohan Chandraker, Ziyu Jiang
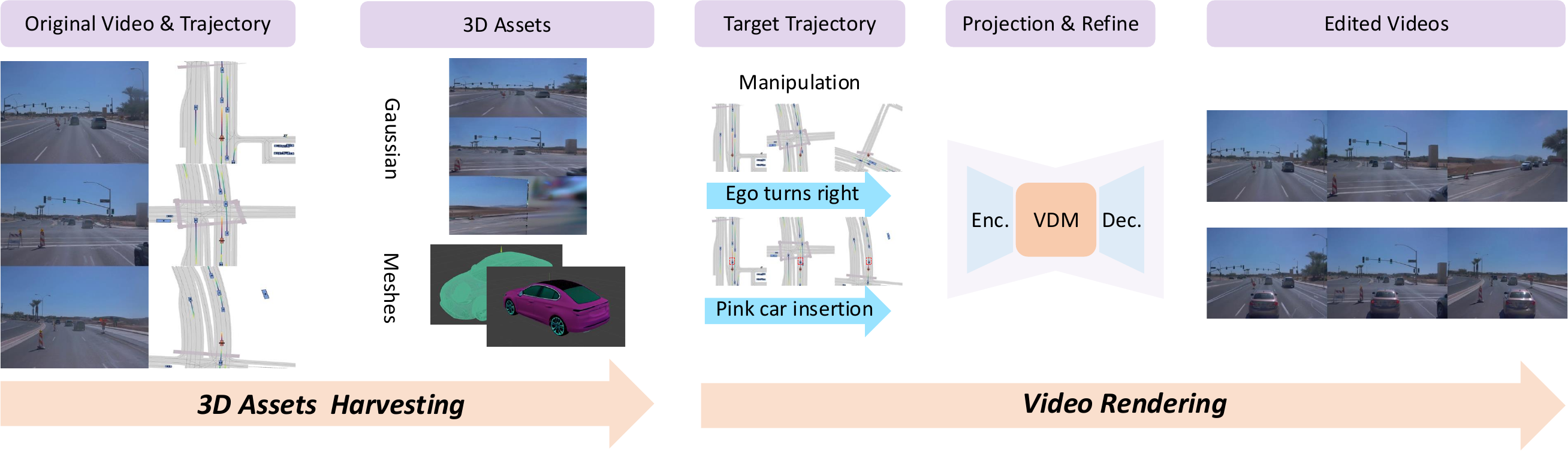
Controllable driving scene generation is critical for realistic and scalable autonomous driving simulation, yet existing approaches struggle to jointly achieve photorealism and precise control. We introduce HorizonForge, a unified framework that reconstructs scenes as editable Gaussian Splats and Meshes, enabling fine-grained 3D manipulation and language-driven vehicle insertion. Edits are rendered through a noise-aware video diffusion process that enforces spatial and temporal consistency, producing diverse scene variations in a single feed-forward pass without per-trajectory optimization. To standardize evaluation, we further propose HorizonSuite, a comprehensive benchmark spanning ego- and agent-level editing tasks such as trajectory modifications and object manipulation. Extensive experiments show that the Gaussian-Mesh representation delivers substantially higher fidelity than alternative 3D representations, and that temporal priors from video diffusion are essential for coherent synthesis. HorizonForge establishes a simple yet powerful paradigm for photorealistic, controllable driving simulation, achieving an 83.4% user-preference gain and a 25.19% FID improvement over the second best state-of-the-art method.
ICCV 2025 | LangTraj: Diffusion Model and Dataset for Language-Conditioned Trajectory Simulation
Wei-Jer Chang, Wei Zhan, Masayoshi Tomizuka, Manmohan Chandraker, Francesco Pittaluga

Evaluating autonomous vehicles with controllability allows for scalable testing in counterfactual or structured settings, improving both efficiency and safety. We introduce LangTraj, a language-conditioned scene-diffusion model that simulates the joint behavior of all agents in traffic scenarios. By conditioning on natural language inputs, LangTraj enables flexible and intuitive control over interactive behaviors, generating nuanced and realistic scenarios. Unlike prior approaches that rely on domain-specific guidance functions, LangTraj incorporates language conditioning during training for more intuitive traffic simulation control. We further propose a novel closed-loop training strategy for diffusion models to enhance realism in closed-loop simulation. To support language-conditioned simulation, we develop a scalable pipeline for annotating agent-agent interactions and single-agent behaviors, which we use to develop InterDrive, a large-scale dataset of 150k human-labeled annotations offering diverse and interactive labels. Validated on the Waymo Open Motion Dataset, LangTraj demonstrates strong performance in realism, language controllability, and language-conditioned safety-critical simulation.
U.S. DOT 2025 | Winner of U.S. Department of Transportation Intersection Safety Challenge ($750,000)
NEC Labs America, NEC America, University of Hawaii

The Intersection Safety Challenge aims to advance intersection safety by developing, prototyping, and testing innovative systems that leverage emerging machine-learning technologies. These systems are designed to detect and mitigate unsafe conditions involving both vehicles and vulnerable road users at roadway intersections. The competition featured a series of technical challenges—including sensor fusion, classification, path prediction, and conflict detection—utilizing real-world sensor data provided by the U.S. Department of Transportation. Our winning approach integrated sensor fusion across multiple modalities, including LiDAR, RGB cameras, thermal imaging, and traffic signal data. This enabled highly accurate 3D localization, open-vocabulary detection (capable of recognizing even previously unseen objects), and multi-modal probabilistic path prediction. These capabilities were then combined to effectively predict and mitigate potential conflicts at intersections.
ECCV 2024 | SafeSim: Safety-Critical Closed-Loop Traffic Simulation with Diffusion-Controllable Adversaries
Wei-Jer Chang, Francesco Pittaluga, Wei Zhan, Masayoshi Tomizuka, Manmohan Chandraker
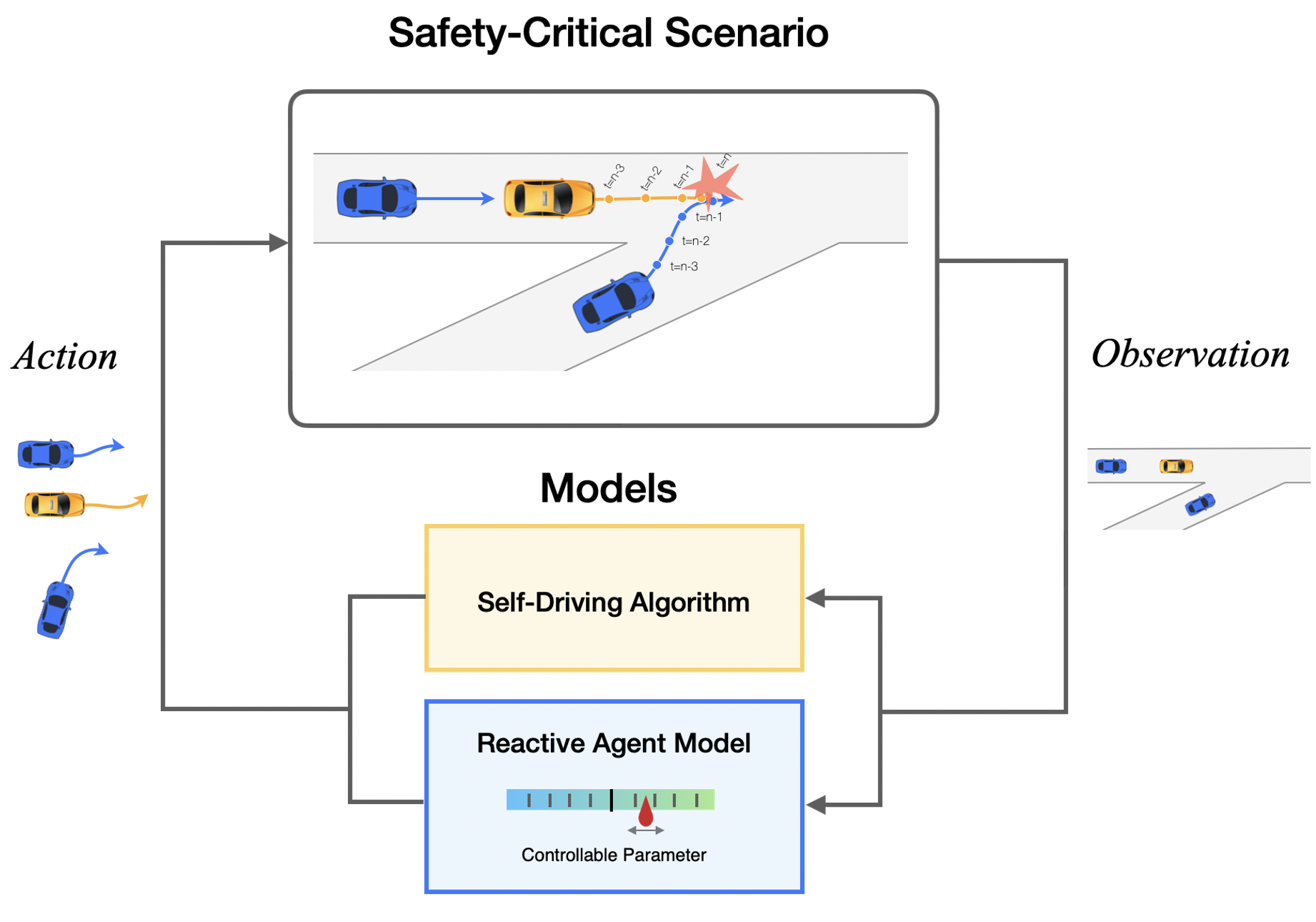
Evaluating the performance of autonomous vehicle planning algorithms necessitates simulating long-tail traffic scenarios. Traditional methods for generating safety-critical scenarios often fall short in realism and controllability. Furthermore, these techniques generally neglect the dynamics of agent interactions. To mitigate these limitations, we introduce a novel closed-loop simulation framework rooted in guided diffusion models. Our approach yields two distinct advantages: 1) the generation of realistic long-tail scenarios that closely emulate real-world conditions, and 2) enhanced controllability, enabling more comprehensive and interactive evaluations. We achieve this through novel guidance objectives that enhance road progress while lowering collision and off-road rates. We develop a novel approach to simulate safety-critical scenarios through an adversarial term in the denoising process, which allows the adversarial agent to pose challenges to a planner with plausible maneuvers, while all agents in the scene exhibit reactive and realistic behaviors. We validate our framework empirically using the NuScenes dataset, demonstrating improvements in both realism and controllability. These findings affirm that guided diffusion models provide a robust and versatile foundation for safety-critical, interactive traffic simulation, extending their utility across the broader landscape of autonomous driving.
2023 | LLM-Assist: Enhancing Closed-Loop Planning with Language-Based Reasoning
S P Sharan, Francesco Pittaluga, Vijay Kumar B G, Manmohan Chandraker
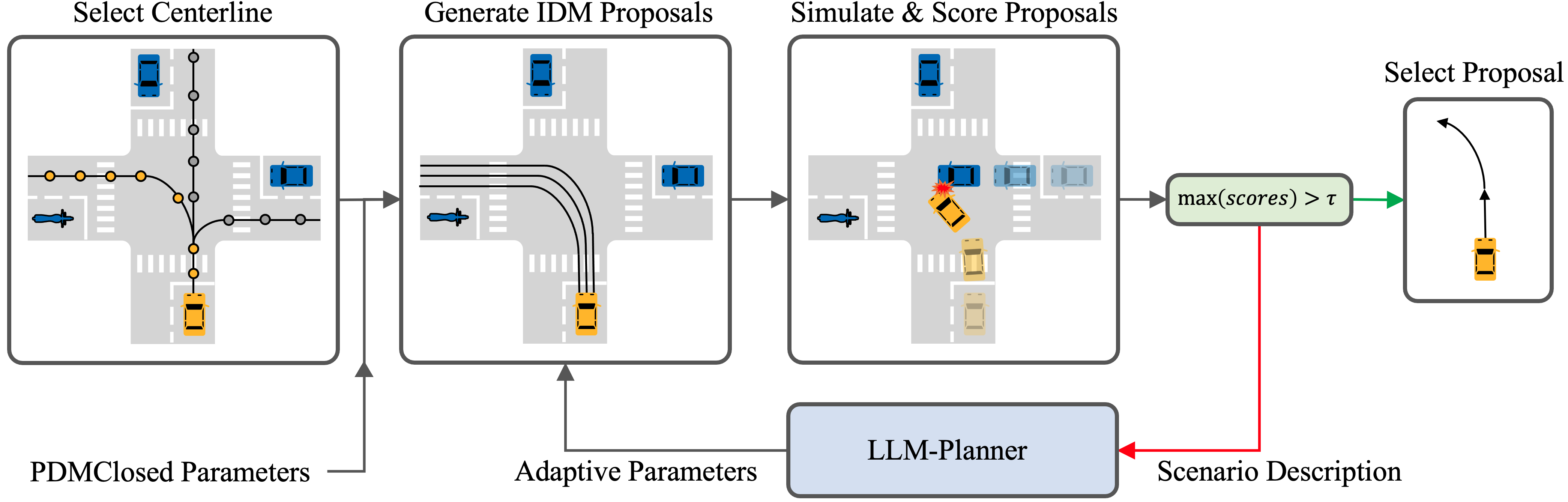
Although planning is a crucial component of the autonomous driving stack, researchers have yet to develop robust planning algorithms that are capable of safely handling the diverse range of possible driving scenarios. Learning-based planners suffer from overfitting and poor long-tail performance. On the other hand, rule-based planners generalize well, but might fail to handle scenarios that require complex driving maneuvers. To address these limitations, we investigate the possibility of leveraging the common-sense reasoning capabilities of Large Language Models (LLMs) such as GPT4 and Llama 2 to generate plans for self-driving vehicles. In particular, we develop a novel hybrid planner that leverages a conventional rule-based planner in conjunction with an LLM-based planner. Guided by commonsense reasoning abilities of LLMs, our approach navigates complex scenarios which existing planners struggle with, produces well-reasoned outputs while also remaining grounded through working alongside the rule-based approach. Through extensive evaluation on the nuPlan benchmark, we achieve state-of-the-art performance, outperforming all existing pure learning- and rule-based methods across most metrics.
CVPR 2021 (Oral) | Divide-and-Conquer for Lane-Aware Diverse Trajectory Prediction
Sriram N N, Ramin Moslemi, Francesco Pittaluga, Buyu Liu
We addresses two key challenges in trajectory prediction: learning multimodal outputs and improving predictions by imposing constraints using driving knowledge. Recent methods have achieved strong performances using Multi-Choice Learning objectives like winner-takes-all (WTA), but are highly depend on their initialization to provide diverse outputs. We propose a novel Divide-And-Conquer (DAC) approach that acts as a better initialization for the WTA objective, resulting in diverse outputs without any spurious modes. Further, we introduce a novel trajectory prediction framework called ALAN that uses existing lane center lines as anchors to constrained predicted trajectories.
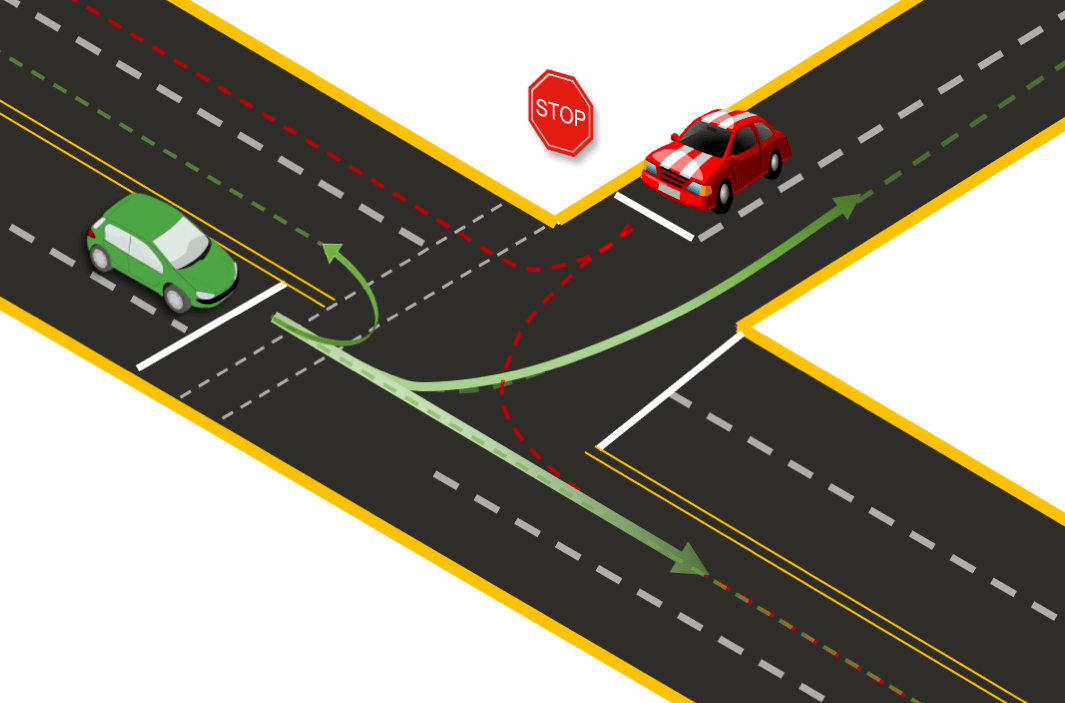
ECCV 2020 | SMART: Simultaneous Multi-Agent Recurrent Trajectory Prediction
Sriram N N, Buyu Liu, Francesco Pittaluga, Manmohan Chandraker
We propose advances that address two key challenges in future trajectory prediction: (i) multimodality in both training data and predictions and (ii) constant time inference regardless of number of agents. Existing trajectory predictions are fundamentally limited by lack of diversity in training data, which is difficult to acquire with sufficient coverage of possible modes. Our first contribution is an automatic method to simulate diverse trajectories in the top-view. It uses pre-existing datasets and maps as initialization, mines existing trajectories to represent realistic driving behaviors and uses a multi-agent vehicle dynamics simulator to generate diverse new trajectories that cover various modes and are consistent with scene layout constraints. Our second contribution is a novel method that generates diverse predictions while accounting for scene semantics and multi-agent interactions, with constant-time inference independent of the number of agents. We propose a convLSTM with novel state pooling operations and losses to predict scene-consistent states of multiple agents in a single forward pass, along with a CVAE for diversity.
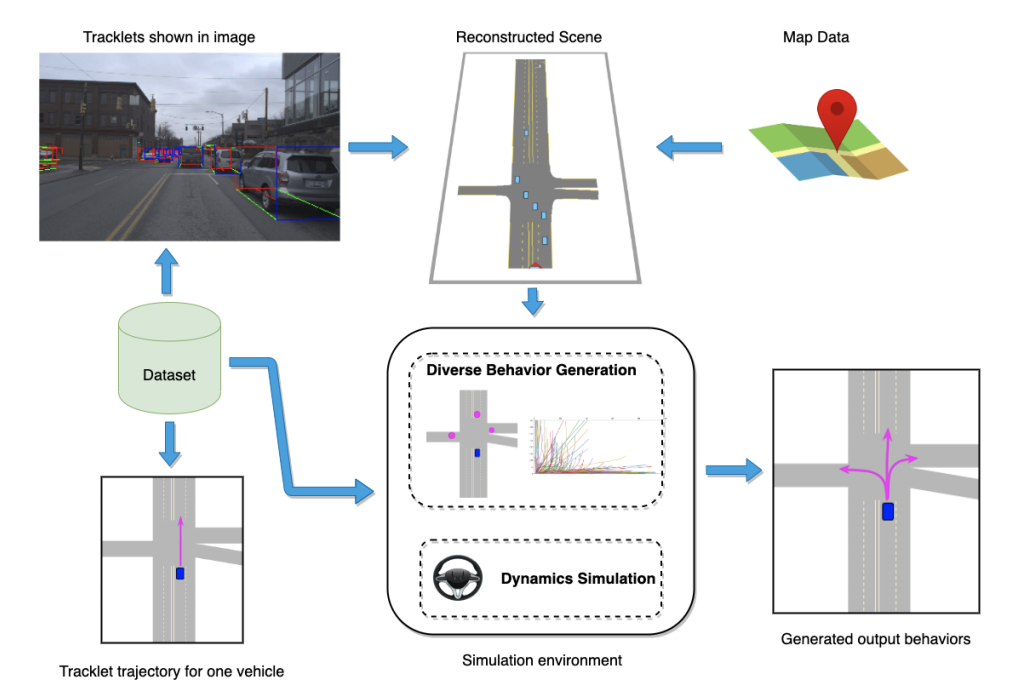
3DV 2020 | Towards MEMS-based Adaptive LIDAR
Francesco Pittaluga, Zaid Tasneem, Justin Folden, Brevin Tilmon, Ayan Chakrabarti, Sanjeev J. Koppal
Unlike most artificial sensors, animal eyes foveate, or distribute resolution where it is needed. This is computationally efficient, since neuronal resources are concentrated on regions of interest. Similarly, we believe that an adaptive LIDAR would be useful on power/cost constrained platforms. We present a proof-of-concept LIDAR design that allows adaptive real-time measurements according to dynamically specified measurement patterns. We describe our optical setup and calibration, which enables fast sparse depth measurements using a scanning MEMS (micro-electro-mechanical) mirror. We validate the efficacy of our prototype LIDAR design by testing on static and dynamic scenes spanning a range of environments. We show CNN-based depth-map completion experiments which demonstrate that our sensor can realize adaptive depth sensing for dynamic scenes.
Privacy-Preserving Vision and Sensing
TCI 2024 | OpEnCam: Lensless Optical Encryption Camera
Salman S. Khan, Xiang Yu, Kaushik Mitra, Manmohan Chandraker, Francesco Pittaluga
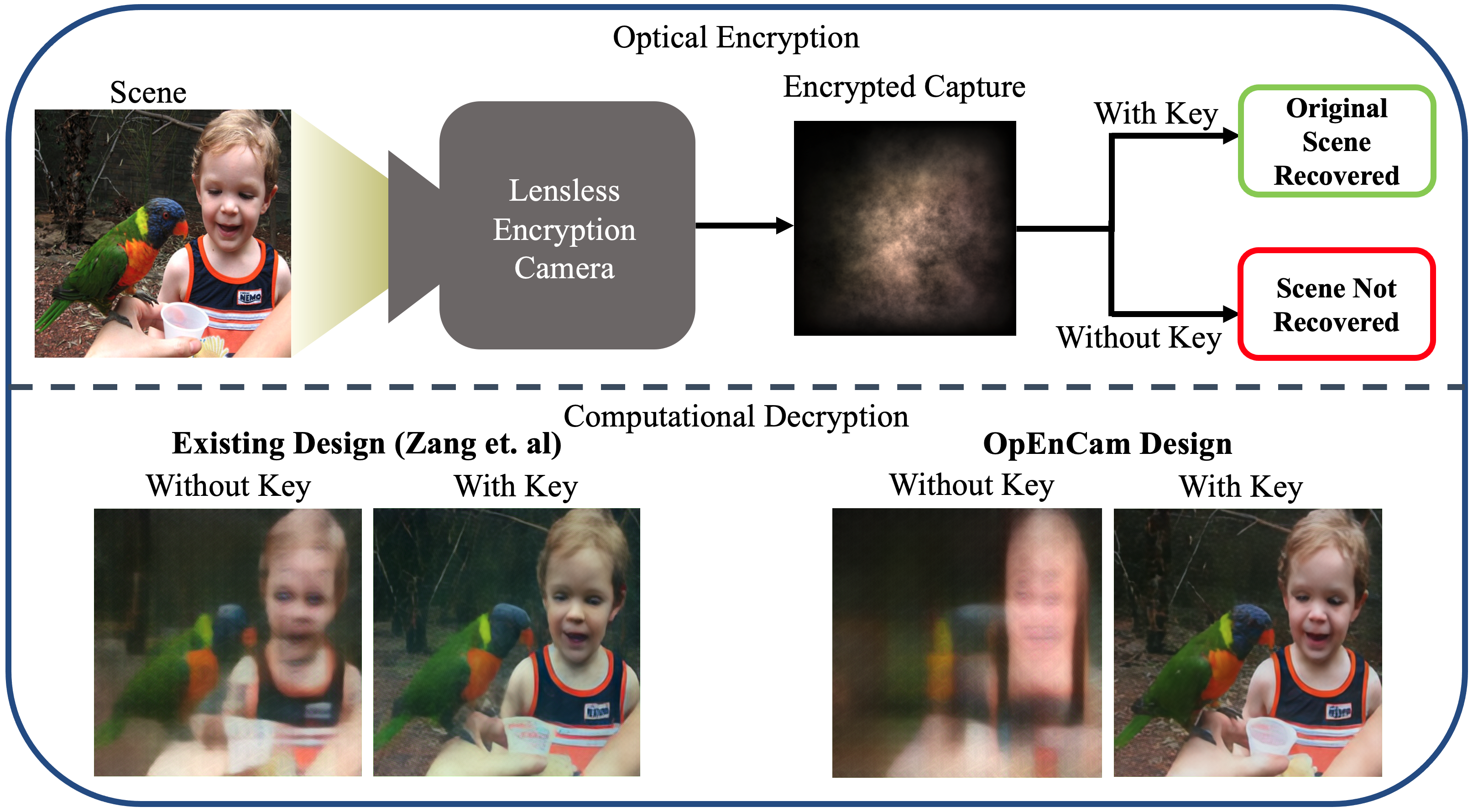
Lensless cameras multiplex the incoming light before it is recorded by the sensor. This ability to multiplex the incoming light has led to the development of ultra-thin, high-speed, and single-shot 3D imagers. Recently, there have been various attempts at demonstrating another useful aspect of lensless cameras - their ability to preserve the privacy of a scene by capturing encrypted measurements. However, existing lensless camera designs suffer numerous inherent privacy vulnerabilities. To demonstrate this, we develop the first comprehensive attack model for encryption cameras, and propose OpEnCam -- a novel lensless optical encryption camera design that overcomes these vulnerabilities. OpEnCam encrypts the incoming light before capturing it using the modulating ability of optical masks. Recovery of the original scene from an OpEnCam measurement is possible only if one has access to the camera's encryption key, defined by the unique optical elements of each camera. Our OpEnCam design introduces two major improvements over existing lensless camera designs - (a) the use of two co-axially located optical masks, one stuck to the sensor and the other a few millimeters above the sensor and (b) the design of mask patterns, which are derived heuristically from signal processing ideas. We show, through experiments, that OpEnCam is robust against a range of attack types while still maintaining the imaging capabilities of existing lensless cameras. We validate the efficacy of OpEnCam using simulated and real data. Finally, we built and tested a prototype in the lab for proof-of-concept.
NeurIPS 2023 | DP-Mix: Mixup-based Data Augmentation for Differentially Private Learning
Wenxuan Bao, Francesco Pittaluga, Vijay Kumar B G, Vincent Bindschaedler
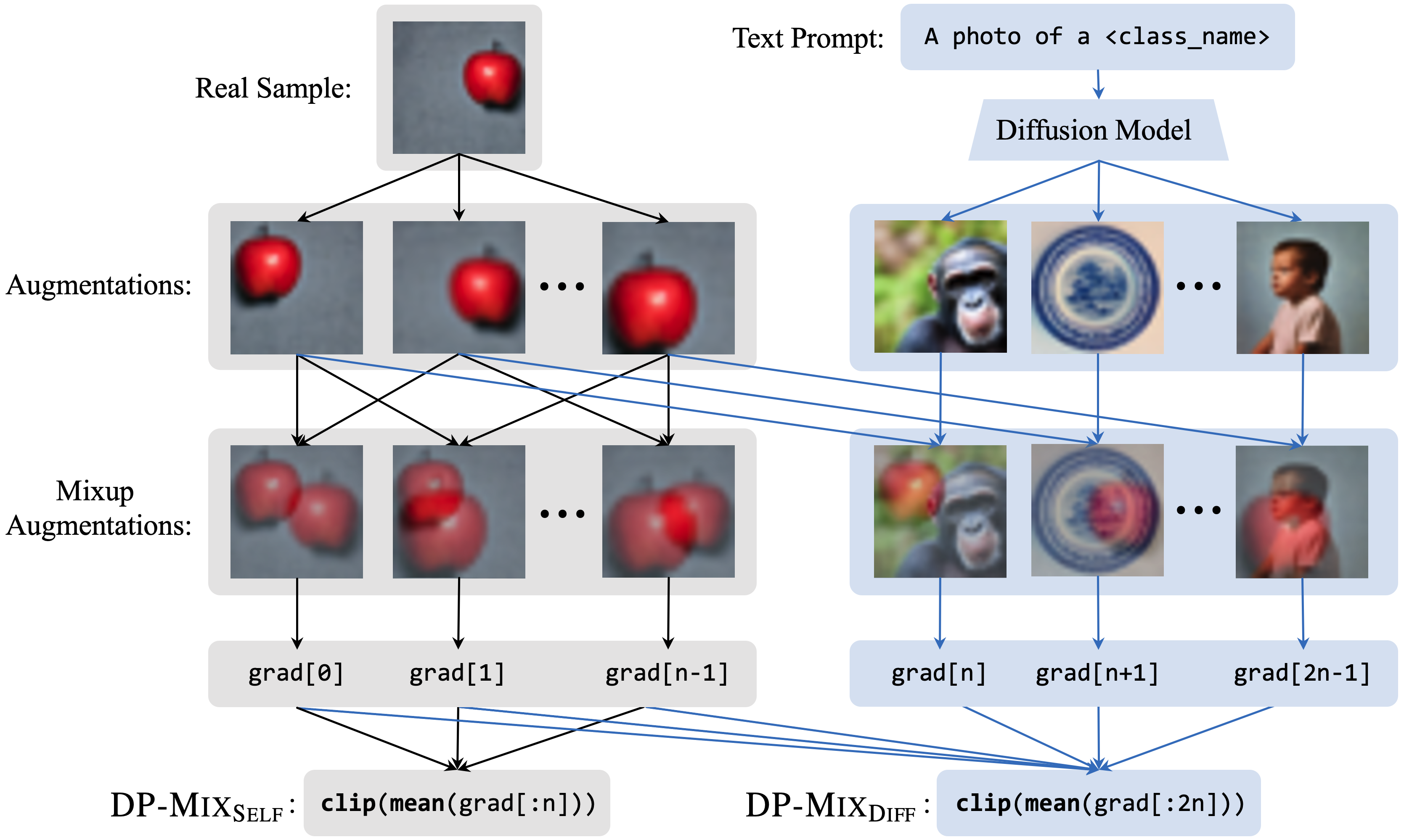
Data augmentation techniques, such as simple image transformations and combinations, are highly effective at improving the generalization of computer vision models, especially when training data is limited. However, such techniques are fundamentally incompatible with differentially private learning approaches, due to the latter’s built-in assumption that each training image’s contribution to the learned model is bounded. In this paper, we investigate why naive applications of multi-sample data augmentation techniques, such as mixup, fail to achieve good performance and propose two novel data augmentation techniques specifically designed for the constraints of differentially private learning. Our first technique, DP-Mixself, achieves SoTA classification performance across a range of datasets and settings by performing mixup on self-augmented data. Our second technique, DP-Mixdiff, further improves performance by incorporating synthetic data from a pre-trained diffusion model into the mixup process.
ICCV 2023 | LDP-Feat: Image Features with Local Differential Privacy
Francesco Pittaluga, Bingbing Zhuang

Modern computer vision services often require users to share raw feature descriptors with an untrusted server. This presents an inherent privacy risk, as raw descriptors may be used to recover the source images from which they were extracted. To address this issue, researchers recently proposed privatizing image features by embedding them within an affine subspace containing the original feature as well as adversarial feature samples. In this paper, we propose two novel inversion attacks to show that it is possible to (approximately) recover the original image features from these embeddings, allowing us to recover privacy-critical image content. In light of such successes and the lack of theoretical privacy guarantees afforded by existing visual privacy methods, we further propose the first method to privatize image features via local differential privacy, which, unlike prior approaches, provides a guaranteed bound for privacy leakage regardless of the strength of the attacks. In addition, our method yields strong performance in visual localization as a downstream task while enjoying the privacy guarantee.
NeurIPSW 2022 | Voting-based Approaches For Differentially Private Federated Learning
Yuqing Zhu, Xiang Yu, Yi-Hsuan Tsai, Francesco Pittaluga, Masoud Faraki, Manmohan chandraker, Yu-Xiang Wang
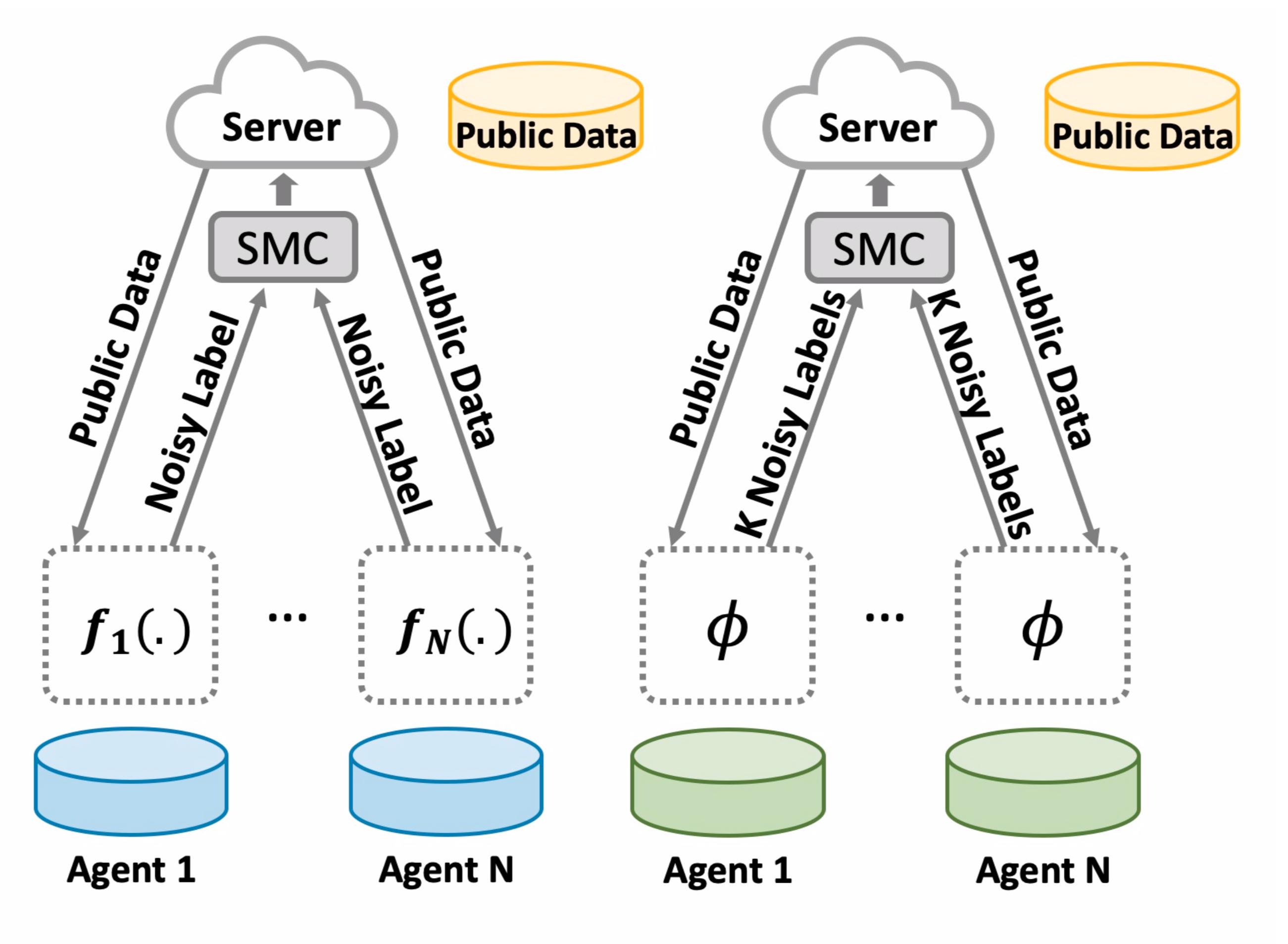
While federated learning enables distributed agents to collaboratively train a centralized model without sharing data with each other, it fails to protect users against inference attacks that mine private information from the centralized model. Thus, facilitating federated learning methods with differential privacy becomes attractive. Existing algorithms based on privately aggregating clipped gradients require many rounds of communication, which may not converge, and cannot scale up to large-capacity models due to explicit dimension-dependence in its added noise. In this paper, we adapt the knowledge transfer model of private learning from PATE, as well as the recent alternative PrivateKNN to the federated learning setting. The key difference is that our method privately aggregates the labels from the agents in a voting scheme, instead of aggregating the gradients, hence avoiding the dimension dependence and achieving significant savings in communication cost.
ECCV 2022 | Learning Phase Mask for Privacy-Preserving Passive Depth Estimation
Zaid Tasneem, Giovanni Milione, Yi-Hsuan Tsai, Xiang Yu, Ashok Veeraraghavan, Manmohan Chandraker, Francesco Pittaluga
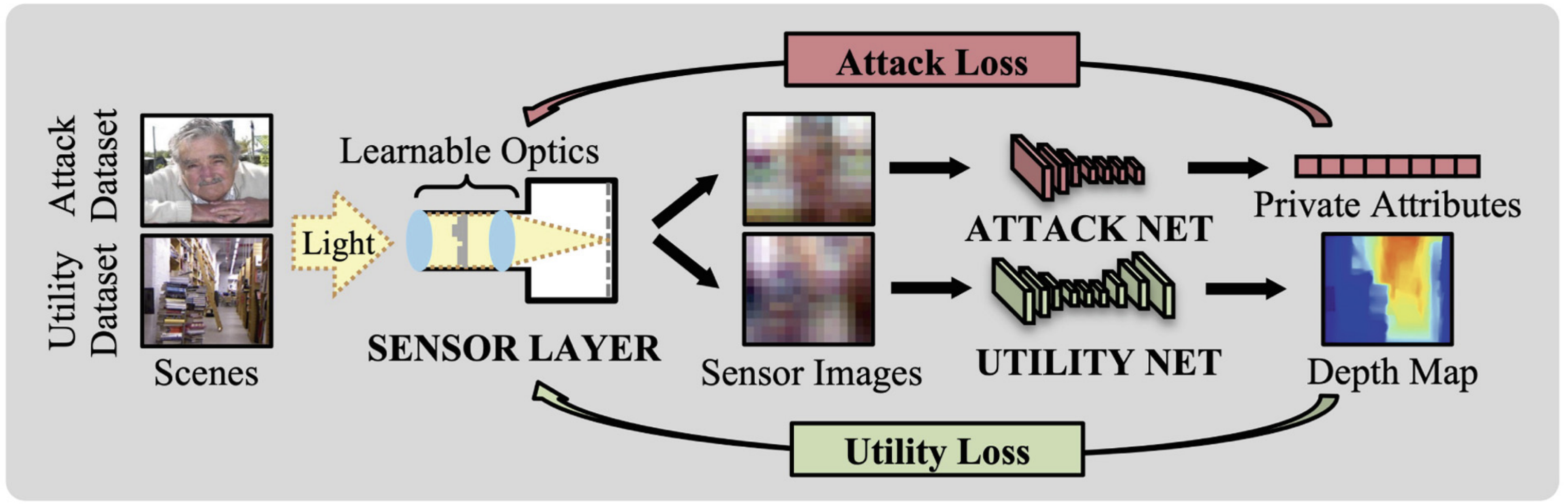
With over a billion sold each year, cameras are not only becoming ubiquitous, but are driving progress in a wide range of domains such as mixed reality, robotics, and more. However, severe concerns regarding the privacy implications of camera-based solutions currently limit the range of environments where cameras can be deployed. The key question we address is: Can cameras be enhanced with a scalable solution to preserve users’ privacy without degrading their machine intelligence capabilities? Our solution is a novel end-to-end adversarial learning pipeline in which a phase mask placed at the aperture plane of a camera is jointly optimized with respect to privacy and utility objectives. We conduct an extensive design space analysis to determine operating points with desirable privacy-utility tradeoffs that are also amenable to sensor fabrication and real-world constraints. We demonstrate the first working prototype that enables passive depth estimation while inhibiting face identification.
CVPR 2019 (Oral & Best Paper Finalist) | Revealing Scenes by Inverting Structure from Motion Reconstructions
Francesco Pittaluga, Sanjeev J. Koppal, Sing Bing Kang, Sudipta Sinha

Many 3D vision systems utilize pose and localization from a pre-captured 3D point cloud. Such 3D models are often obtained using structure from motion (SfM), after which the images are discarded to preserve privacy. In this paper, we show, for the first time, that SfM point clouds retain enough information to reveal scene appearance and compromise privacy. We present a privacy attack that reconstructs color images of the scene from the point cloud. Our method is based on a cascaded U-Net that takes as input, a 2D image of the points from a chosen viewpoint as well as point depth, color, and SIFT descriptors and outputs an image of the scene from that viewpoint. Unlike previous SIFT inversion methods, we handle highly sparse and irregular inputs and tackle the issue of many unknowns, namely, SIFT keypoint orientation and scale, image source, and 3D point visibility. We evaluate our attack algorithm on public datasets (MegaDepth and NYU Depth V2) and analyze the significance of the point cloud attributes. Finally, we synthesize novel views to create compelling virtual tours of scenes.
WACV 2019 | Learning Privacy-Preserving Encodings through Adversarial Training
Francesco Pittaluga, Sanjeev J. Koppal, Ayan Chakrabarti

We present a framework to learn privacy preserving encodings of images that inhibit inference of chosen private attributes, while allowing recovery of other desirable information. Rather than simply inhibiting a given fixed pretrained estimator, our goal is that an estimator be unable to learn to accurately predict the private attributes even with knowledge of the encoding function. We use a natural adversarial optimization-based formulation for this training the encoding function against a classifier for the private attribute, with both modeled as deep neural networks. The key contribution of our work is a stable and convergent optimization approach that is successful at learning an encoder with our desired properties maintaining utility while inhibiting inference of private attributes, not just within the adversarial optimization, but also by classifiers that are trained after the encoder is fixed. We adopt a rigorous experimental protocol for verification wherein classifiers are trained exhaustively till saturation on the fixed encoders. We evaluate our approach on tasks of real-world complexity learning high-dimensional encodings that inhibit detection of different scene categories and find that it yields encoders that are resilient at maintaining privacy.
CVPRW 2019 | Privacy-Preserving Action Recognition using Coded Aperture Videos
Zihao W. Wang, Vibhav Vineet, Francesco Pittaluga, Sudipta Sinha, Oliver Cossairt, Sing Bing Kang
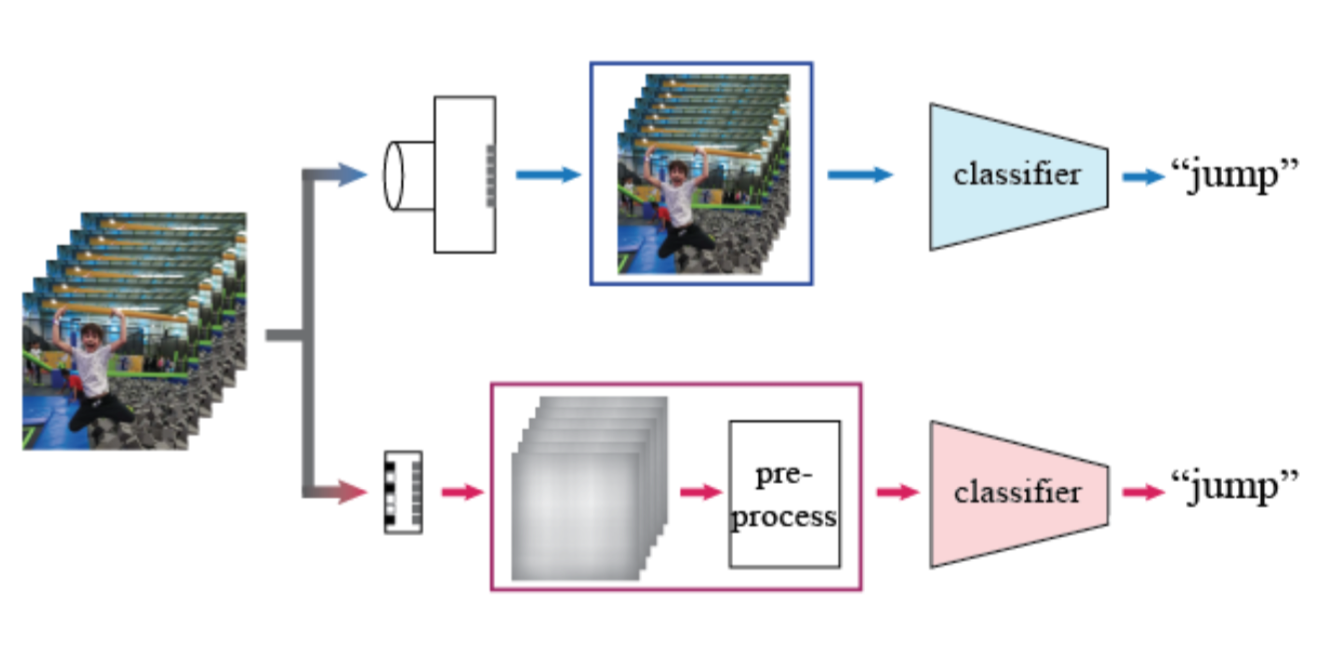
The risk of unauthorized remote access of streaming video from networked cameras underlines the need for stronger privacy safeguards. Towards this end, we simulate a lens-free coded aperture (CA) camera as an appearance encoder, i.e., the first layer of privacy protection. Our goal is human action recognition from coded aperture videos for which the coded aperture mask is unknown and does not require reconstruction. We insert a second layer of privacy protection by using non-invertible motion features based on phase correlation and log-polar transformation. Phase correlation encodes translation while the log polar transformation encodes in-plane rotation and scaling. We show the key property of the translation features being mask-invariant. This property allows us to simplify the training of classifiers by removing reliance on a specific mask design. Results based on a subset of the UCF and NTU datasets show the feasibility of our system.
PAMI 2017 & CVPR 2015 | Pre-Capture Privacy for Small Vision Sensors
Francesco Pittaluga and Sanjeev J. Koppal

The next wave of micro and nano devices will create a world with trillions of small networked cameras. This will lead to increased concerns about privacy and security. Most privacy preserving algorithms for computer vision are applied after image/video data has been captured. We propose to use privacy preserving optics that filter or block sensitive information directly from the incident light-field before sensor measurements are made, adding a new layer of privacy. In addition to balancing the privacy and utility of the captured data, we address trade-offs unique to miniature vision sensors, such as achieving high-quality field-of-view and resolution within the constraints of mass and volume. Our privacy preserving optics enable applications such as depth and thermal sensing and full-body motion tracking. While we demonstrate applications on macro-scale devices (smartphones, webcams, etc.) our theory has impact for smaller devices.
ICCP 2016 | Sensor-level Privacy for Thermal Cameras
Francesco Pittaluga, Aleksandar Zivkovic, Sanjeev J. Koppal

As cameras turn ubiquitous, balancing privacy and utility becomes crucial. To achieve both, we enforce privacy at the sensor level, as incident photons are converted into an electrical signal and then digitized into image measurements. We present sensor protocols and accompanying algorithms that degrade facial information for thermal sensors, where there is usually a clear distinction between humans and the scene. By manipulating the sensor processes of gain, digitization, exposure time, and bias voltage, we are able to provide privacy during the actual image formation process and the original face data is never directly captured or stored. We show privacy-preserving thermal imaging applications such as temperature segmentation, night vision, gesture recognition and HDR imaging.