CVPR 2019
Revealing Scenes by Inverting Structure from Motion Reconstructions
Effect of Input Attributes
Four example results from models trained with different sets of input attributes. For each example, the left image depicts the original image and the right image shows the result of CoarseNet + RefineNet. Hover over the buttons below to compare the results.


Original Image








Reconstruction


Original Image








Reconstruction
Effect of Input Sparsity
Four example results from the same model, but for inputs with different degrees of sparsity (% of SfM points kept). For each example, the left image shows the input sparsity and the right image shows the result of CoarseNet + RefineNet. CoarseNet and RefineNet were trained on depth, color and SIFT. Hover over the three buttons below to compare the results.

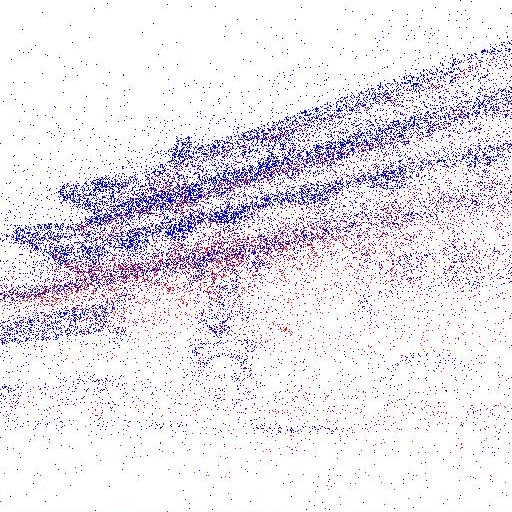



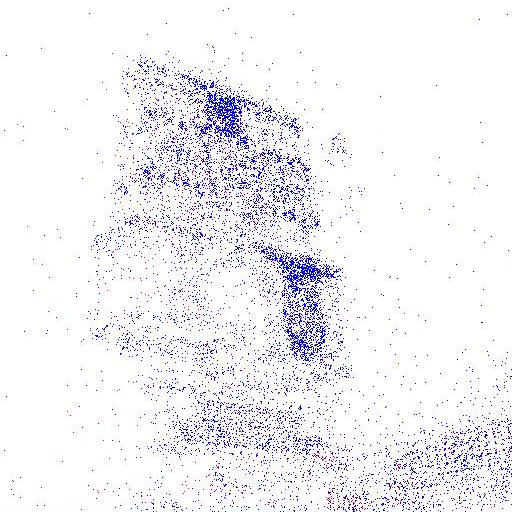
Input Points






Reconstruction






Input Points






Reconstruction
Effect of RefineNet
Four examples comparing results from CoarseNet and CoarseNet + RefineNet. For each example, two images are shown. The left image is the result of a model trained on depth and SIFT as input attributes. The right image is the result of a model trained on depth, color and SIFT as input attributes. Hover over the two buttons below to compare the results.




Depth + SIFT




Depth + SIFT + Color




Depth + SIFT




Depth + SIFT + Color